🎓A Linguistic Study on Relevance Modeling in Information Retrieval
1. ABSTRACT
IR已经成为许多现实世界应用中的核心任务,例如网络搜索引擎,问题应答系统,会话机器人等
IR任务中的相关性的定义和建模在信息科学和计算机科学研究领域始终是一直是关键挑战。
具体来说,我们试图研究以下两个问题
1、三种相关性统一模型(对应三种信息检索任务)在 对于文本的自然语言理解层面真的有不同吗?
2、如果确实不同,如何将三种IR任务的内在异质性应用到 相关性模型中,并提高相关性模型的表现?
2. Introduction
3. Retrieval tasks in information retrieval
3.1 Document Retrieval
查询和文档之间的长度异质性。
用户查询通常很短,而且不明确的意图,在大多数情况下仅包括几个关键词。平均查询长度约为2.35个词
这些文件通常从万维网收集,并且具有更长的文本长度,从多个句子到几个段落。
3.2 Answer Retrieval
问题通常是自然语言,这些语言是良好的句子,并具有更明确的意图描述
答案通常是短文本
答案不仅应该与局部相关但也正确解决问题
早期的统计方法专注于复杂的特征工程
近年来,端到端的神经模型已应用于相关性建模
3.3 Response Retrieval
响应检索是自动对话系统中的核心任务,Apple Siri,Google Now,和Microsoft 小冰
对一个输入话语,从话存储库中选择正确的响应
在多轮响应检索中,每一个输入话语都存在一个对话背景,包含历史对话
输入话语和候选响应通常是短句子,这些句子在形式中均匀。
响应检索的相关性通常是指某些语义对应(或相干结构),这在定义上是很广泛的
例如,给定输入话语“omg我这么一大把岁数还得了近视眼”,响应可以从一般(例如,“真的吗?”)到特定的(例如,“是啊,希望收到一副眼镜作为礼物“)
因此,模拟一致性并避免在响应检索中的一般琐事反应(避免啰嗦)通常是至关重要的
4. Probing analysis(探测分析)
4.1 The Probing Method
分析每个IR任务的Bert-base和bert-ft之间的每个探测任务的性能差距
4.2 Probing Tasks
4.2.1 Lexical Tasks(词法)
- 词汇任务专注于词汇在句子,段落或文档中的词汇意义和位置
- Text Chunking (Chunk) :将复杂的文本划分为较小的部分。CoNLL 2000 dataset
- Part-of-Speech Tagging:词性标注。UD-EWT dataset
- Named Entity Recogntion (NER) :命名实体识别。 CoNLL 2003 dataset
4.2.2 Syntactic Tasks(语法)
- 处理句子中单词之间的关系,正确创建句子结构和单词顺序
- Grammatical Error Detection (GED) :语法错误检测。First Certificate in English dataset
- Syntactic Dependence :句法依赖。弧预测和弧分类UD-EWT dataset
- 句法弧依赖关系预测(Synarcpred)是二分类任务,识别两个词之间存在关系。
- 语法弧依赖关系分类(synarccls)是一个多分类任务,假设输入词彼此有关系,识别是哪类关系。
4.2.3 Semantic Tasks(语义)
- Preposition Supersense Disambiguatio STREUSLE 4.0 corpus
- n PS-fxn:介词功能分析。
PS-role:介词角色分析。
coreference arc prediction (CorefArcPred) :代词、实体共指预测.CoNLL dataset
- Semantic Dependence:SemEval 2015 dataset
- SemArcPred: semantic arc dependency prediction, 两个token之间是否语义依存
SemArcCls: semantic arc dependency classification, 两个token语义关系分类
Synonym & Polysemy:同义词,一词多义。crawled 10k sentences
- Keyword extraction:关键词提取。Inspec dataset
- Topic Classification:主题分类。Yahoo! Answers dataset
4.3 Experimental setting
4.3.1 Retrieval model
bert
4.3.2 Retrieval Datasets.
Robust04 NDCG@20
MsMarco MRR@10
Ubuntu recall@1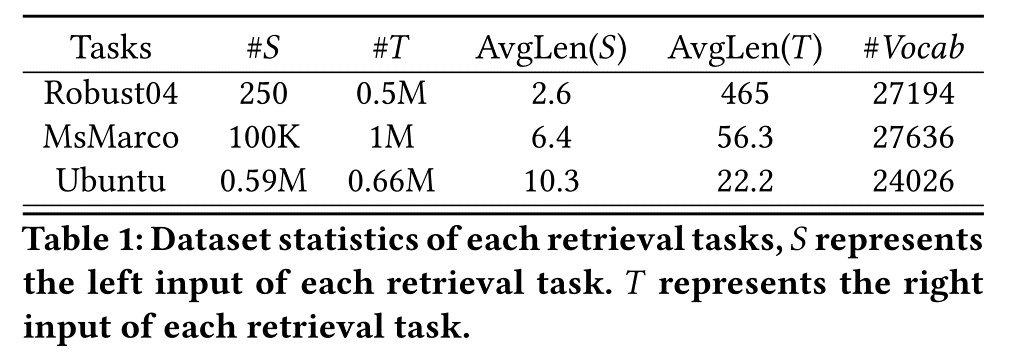
4.4 Results
4.4.1 How does the unified retrieval model perform on each retrieval task?统一模型表现如何
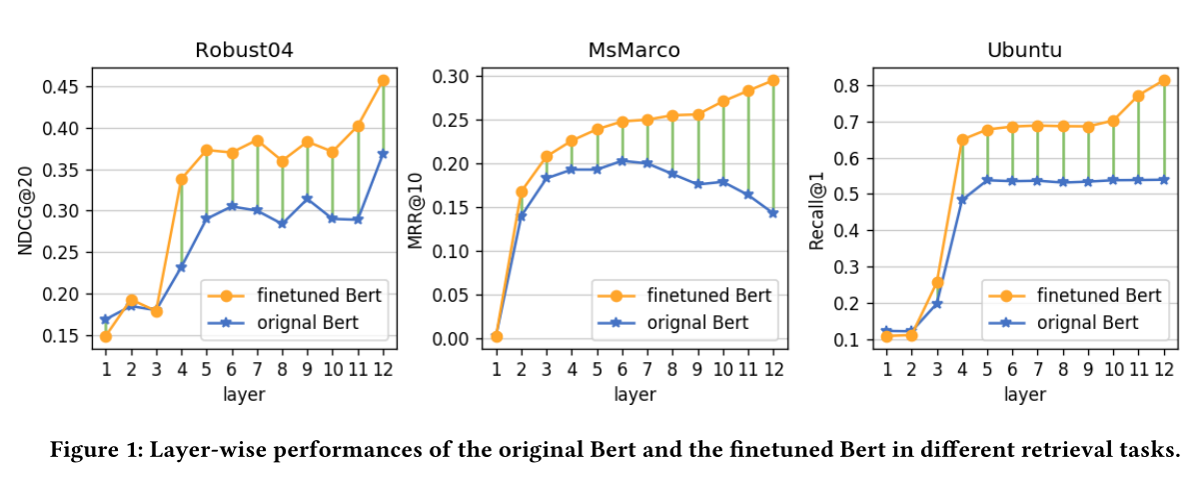
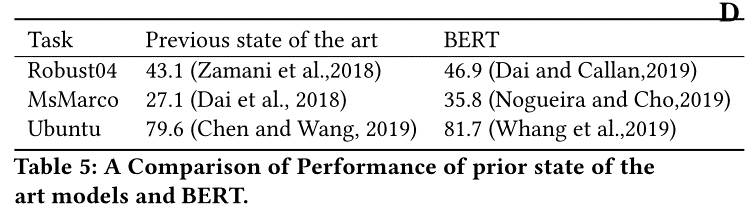
- 预训练模型bert都取得了sota,预训练中学习到的语言学信息对相关度模型还是很有效果的,另外,bert并不一定最后一层效果最好,因此探测实验应该在所有层进行,而不仅仅是最后一层
- Bert-ft > Bert-base,分别提升23.3%, 45.3%和51.6%,表明Bert-ft能够在特定IR任务上学习到任务相关的特定属性。
- Bert-ft 与Bert-base的差距随层数增加而增加,表明Bert-ft中更高的层倾向于学习任务特定特征,而下层学习基本语言特征
4.4.2 Do different IR tasks show different modeling focuses in terms of natural language understanding?在自然语言理解方面,不同的任务是否体现了不同的模型关注点
基于对探测任务的性能差距进行定量分析,我们对IR任务之间的差异进行研究。
从IR任务角度: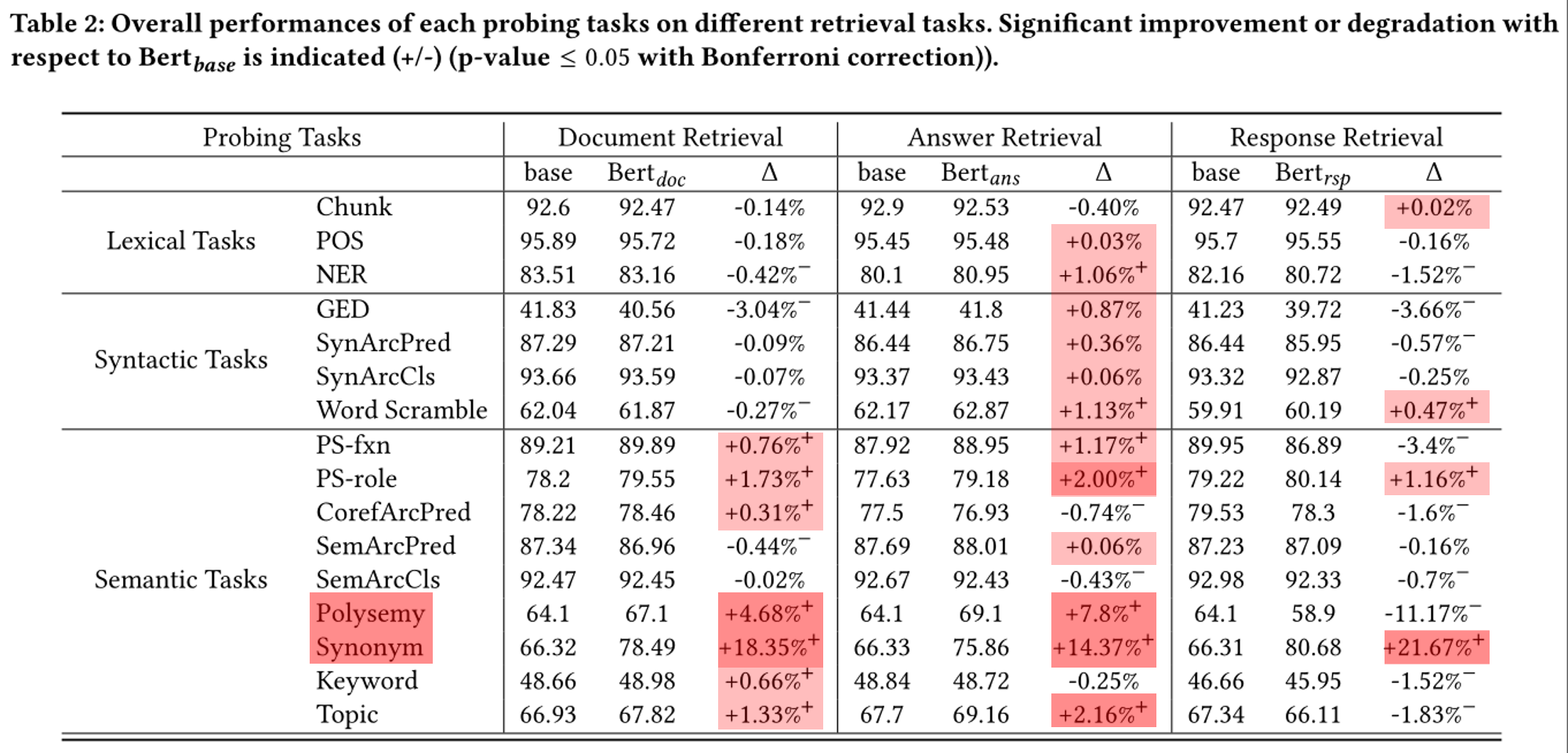
- document retrieval
- answer retrieval
- response retrieval
For response retrieval, it is surprising to see that the performances of most probing tasks (i.e., 12 out of 16) have been decreased by Bertrsp, among which ten drops are significant. It suggests that most linguistic properties encoded by the original Bert has already been sufficient for the relevance modeling in response retrieval. Meanwhile, we can find that Bertrspimproves Synonym while decreases Polysemy significantly, as two extremes. The results demonstrate that response retrieval need to better understand similar words in different contexts than to distinguish the same words in different context.
从探测任务角度:
1、CorefArcPred 、Keyword、NER、GED 结果表明,文档检索中的相关性建模会更多地关注相似的关键字,而答案检索中的相关性建模会更多地关注识别问题和答案的目标实体。
2、Word Scramble 它表明,答案检索和响应检索比文档检索更关心词序和句子结构。Polysem、 Topic 文档检索和答案检索比响应检索更多地关注主题的理解
3、Synonym、 PS-role 捕获所有相关建模任务中的同义词是非常重要的
基于所有上述观察,我们可以得出结论,三个代表检索任务中的相关性建模显示了在自然语言理解方面的焦点相当不同
4.4.3 Do relevance modeling treat their inputs differently in terms of natural language understanding?相关性建模在自然语言理解方面会区别对待他们的左右两个输入吗?
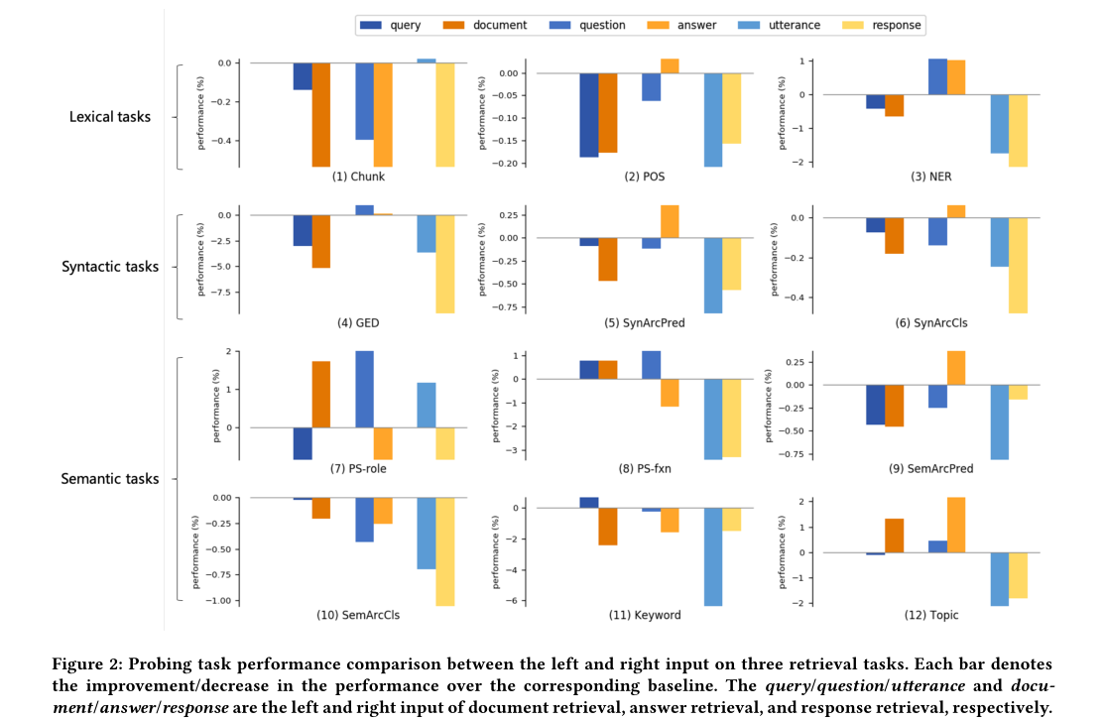
document retrieval
answer retrieval
response retrieval
因此,我们可以发现答案检索(即6逆趋势)是语言视图中固有的最异构的,其次是文档检索(即,3逆趋势)和响应检索(即2反向趋势) )。
5. Intervention analysis(干预分析)
5.1 Intervention Settings
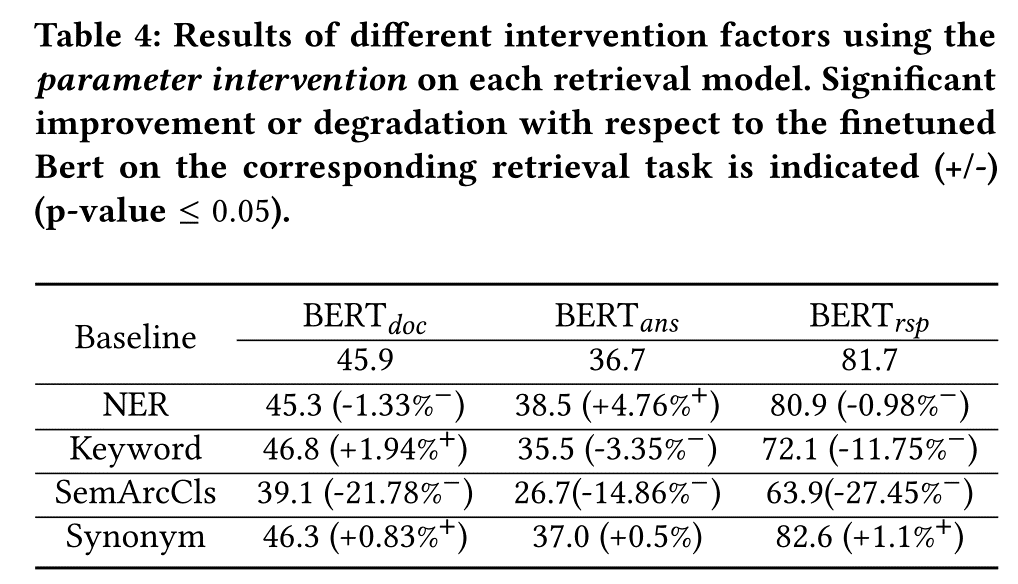
基于以下三个原因选择四个代表性探测任务作为干预因素,即Keyword, NER, Synonym, and SemArcCls
Synonym在三个检索任务都提高了
SemArcCls在三个检索任务都降低了
Feature Intervention:我们将每个因子(e.g.,PER, ORG, LOC in the NER)的标签映射到嵌入空间并将嵌入BERT输入Embeddings
Parameter Intervention:先在 NLU tasks任务上进行微调BERT模型,然后进一步在 三个IR任务上面分别 Finetune 模型。 BERT上面多加了一层MLP适应各个 NLU任务。
Objective Intervention:干预因素以及检索任务进行多任务学习,我们在BERT模型的顶部为每个干预因子添加特定于任务的层。如在BERT顶部添加CRF层,用于序列标记任务(即,ner),并在BERT顶部添加线性层,用于分类任务(即,Keyword, SemArcCls, and Synonym)
5.2 Results
5.2.1 Intervention Methods Comparison.
5.2.2 Intervention Factors Analysis.
6. Related works
6.1 The Relevance Modeling
6.2 The Probing Analysis
7. Conclusion
8. 精句摘要
A major characteristic of document retrieval is the length heterogeneity between queries and documents.
Compared with document retrieval, answer retrieval is more homogeneous and poses different challenges.

